-BeautifulSoup 는 Html 과 Xml 문서를 파싱하기 위한 파이썬 패키지
-웹 스크래핑에 유용한 Html 에서 데이터를 추출하는 데 사용할 수 있는 구문 분석 된 페이지에 대한 구문 분석 트리를 생성
-BeautifulSoup 설치
1. cmd 마우스 오른쪽 눌러서 관리자 권한으로 실행

2. 본인의 파이썬 Scripts 경로를 입력

3. 아래대로 입력하면 다운받아집니다.

| 문 법 | 기 능 |
| find() | 하나의 요소의 값을 읽어오기 |
| find_all() | 전체 데이터를 읽어오기 |
| select() | css 선택자로 요소 여러개를 리스트로 추출 |
| select_one() | css 선택자로 요소하나의 선택자로 요소하나를 추출 |
사용해보자!!~

-find () 사용
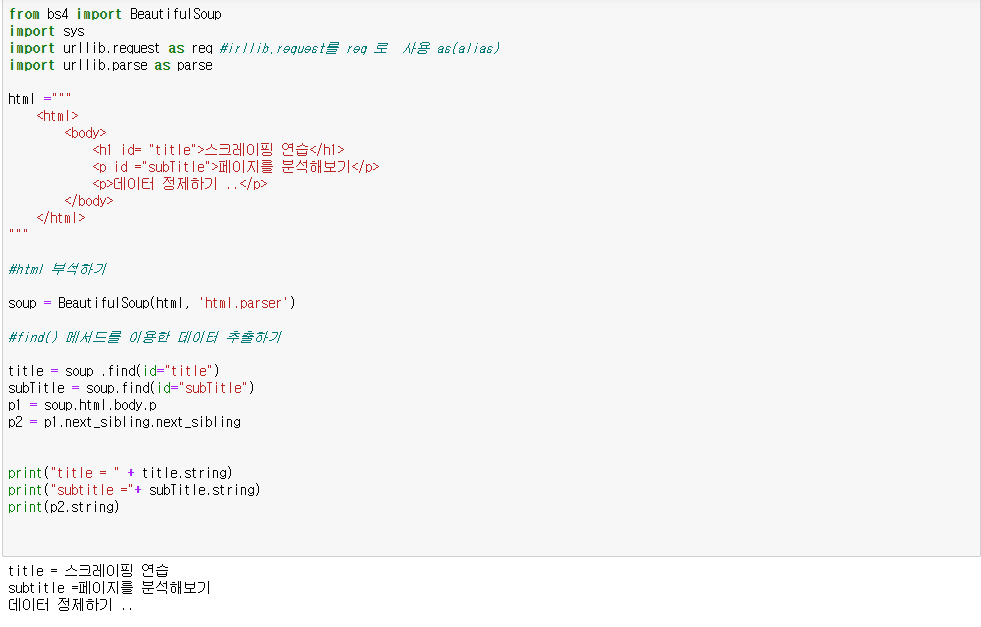
-find_all()
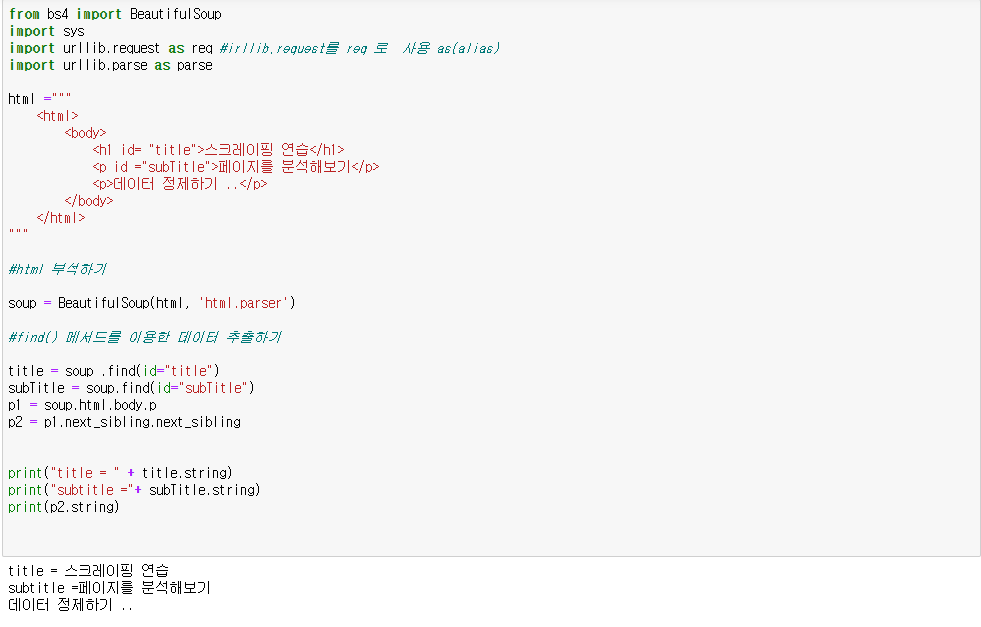

#-*- coding:utf-8 -*-
import sys
import urllib.request #irllib.request를 req 로 사용 as(alias)
from bs4 import BeautifulSoup
rssUrl = "https://finance.naver.com/marketindex/" #네이버 금융
data = urllib.request.urlopen(rssUrl)
soup = BeautifulSoup(data, "html.parser")
ul = oup.select("h3.h_lst > span.blind")
li = soup.select("div.head_info.point_up > span.value")s
while(True):
x = int(input("0~1개의 숫자를 입력해주세요"))
if x == 0:
print("0을 입력하셨습니다.")
print(ul[0].string,"=",li[0].string)
elif x == 1:
print("0을 입력하셨습니다.")
print(ul[1].string,"=",li[1].string)
'파이썬' 카테고리의 다른 글
| (Python) Web site 경로를 따라가 데이터 찾기 (0) | 2020.11.07 |
|---|---|
| (Python) 로또 list 에 담아 뽑기 (0) | 2020.10.13 |
| (Python) 사칙연산 (0) | 2020.10.13 |

